爬虫的开源项目已经满天飞了,各式各样的姿势都有,但是一旦中断维护的项目几乎就算是废掉了,因为网站改版了或者服务升级了。
起初好像是我发现A站上有各种搞笑视频拼接起来的合集,把各种小视频片段拼接起来,然后选择性加一些文案到视频里面,热度都还挺高,所以我想了一下自己实践的可行性。
- 首先需要视频素材,小视频片段很容易爬,比如从Twitter上下手。
- 需要有一个收集方法,比如从某些po主的首页爬,也可以是自己的点赞过包含视频的Twitter。
- 所有爬取的视频存储在本地,生成每日或者每周的视频合集。
- 通过
ffmpeg合并视频,选择性加一些文案。 - 上传视频的自动化。
但是慢慢开始写的时候很多想法又变了,比如:
-
核心的操作其实还是下载和上传的自动化,加上任务的自动化管理,所以就放弃了从Twitter上爬视频。虽然我很久之前就写过爬Twitter的各种媒体资源,但是不想一开始就把重心放在视频片段管理和合并的逻辑上。
-
最后转向从youtube上爬取,因为相比之下不需要管理片段和合并的操作了。
但是这么做还是会有一些侵权风险。
-
上传视频到A站的自动化应该是我给自己挖的最大的坑了吧,因为我用了Selenium,但是没有一次性考虑好运行环境的问题。
-
起初并没有想那么多,打算写完了部署在Google Cloud (GCP) 或者Raspberry Pi 3B+或者家里的mac-mini上的,考虑用Selenium还是没什么大问题的。优先选择GCP的原因是从youtube上下载速度必然非常快,但是上传到A站服务器一定会慢,但是应该还能接受。
-
用Selenium的时候最开始我用的是Chrome/chrome-driver,平时不觉得,但是在gcp上跑的第二天后就提醒我该系统升级了,内存已经超载了,GCP应该是有一个tolerance time,前面几天运行没有问题,但是很快就炸了。由于某些不可描述的原因,我还在薅GCP那300刀的羊毛,创建的实例只有0.6G的最低内存配置,升级系统会加速消费速度,猜测还会影响其他已经在运行的其他服务的带宽,所以最终迁移到了Raspberry Pi上。
-
家里的RPi最近一次用是用来部署一个Kodi结合Plex的家庭影音平台,后来因为搬家的原因所以基本闲置了。我忘了几年前买它时候的配置,那还是一个armv7l的32bit架构。Chrome又坑了我一次,不知道具体从什么时候开始,Google放弃了支持32bit的Chrome for linux。这下完犊子了,我在Debian 9上各种尝试找到最后一个支持32bit的chrome和chromedriver安装包,尝试dpkg离线安装但是死活不成功,好像是依赖库的版本和其他软件不兼容的问题。
-
实在没办法了,Selenium还是支持不少其他webdriver的,优先考虑的自然是Firefox,庆幸的是FF还是一直32bit的(给Mozilla点个赞!),安装过程很顺利。但是运行过程中又碰到了一个奇怪的问题,辗转几次定位到了是virtual display的问题。奇怪的是在GCP上使用Chrome并没有问题,不知道是GCP还是Chrome做了额外的处理。
UPDATE 1:
最终还是没有在RPi上通过Firefox跑起来,Firefox for Raspbian还是更新速度还是赶不上,碰到了marionette不兼容Selenium的问题,找到的解决办法都是建议升级Firefox,最终放弃了。
现在重新部署到阿里云T5 Debian 10上了,x86_64架构,Chromium 79,终于稳定运行了。不过这个服务器不久就要到期了,只能暂时先这么用着再说了。
-
运行方式的选择途中我还想过另一个种奇葩的逻辑:用GCP的优势毕竟是因为youtube下载快,用阿里云/RPi的优势是长传快,为什么不结合一下?没有必要非要让所有代码运行在一个机器下。所以尝试了一下可行性,单独让youtube-downloader-cli相关的代码在GCP上运行,然后通过rsync或者Paramiko把所有视频和数据库(sqlite文件)传回到阿里云/RPi,最后上传到A站等。这种做法又会直接让sqlite数据的状态管理发生冲突。所以至少得先换掉数据库,比如把数据库换成托管在阿里云的MySQL自建库。之所以考虑rsync传输是因为它支持“断点续传”,校验和重试。用Paramiko是因为Python原生的调用方式,但是它内置的SFTP功能和rsync相比我没测试过。
-
为什么不用mac-mini?因为费电….🤣
-
-
交互方式上也发生了一些改变,最开始是基于click interactive模式,但是后来我觉得操作上可以再懒一点儿,运行不想要那么多的人为干预,所以去掉了所有的interactive交互模式,把不会经常变化的参数全部移到配置文件里控制。
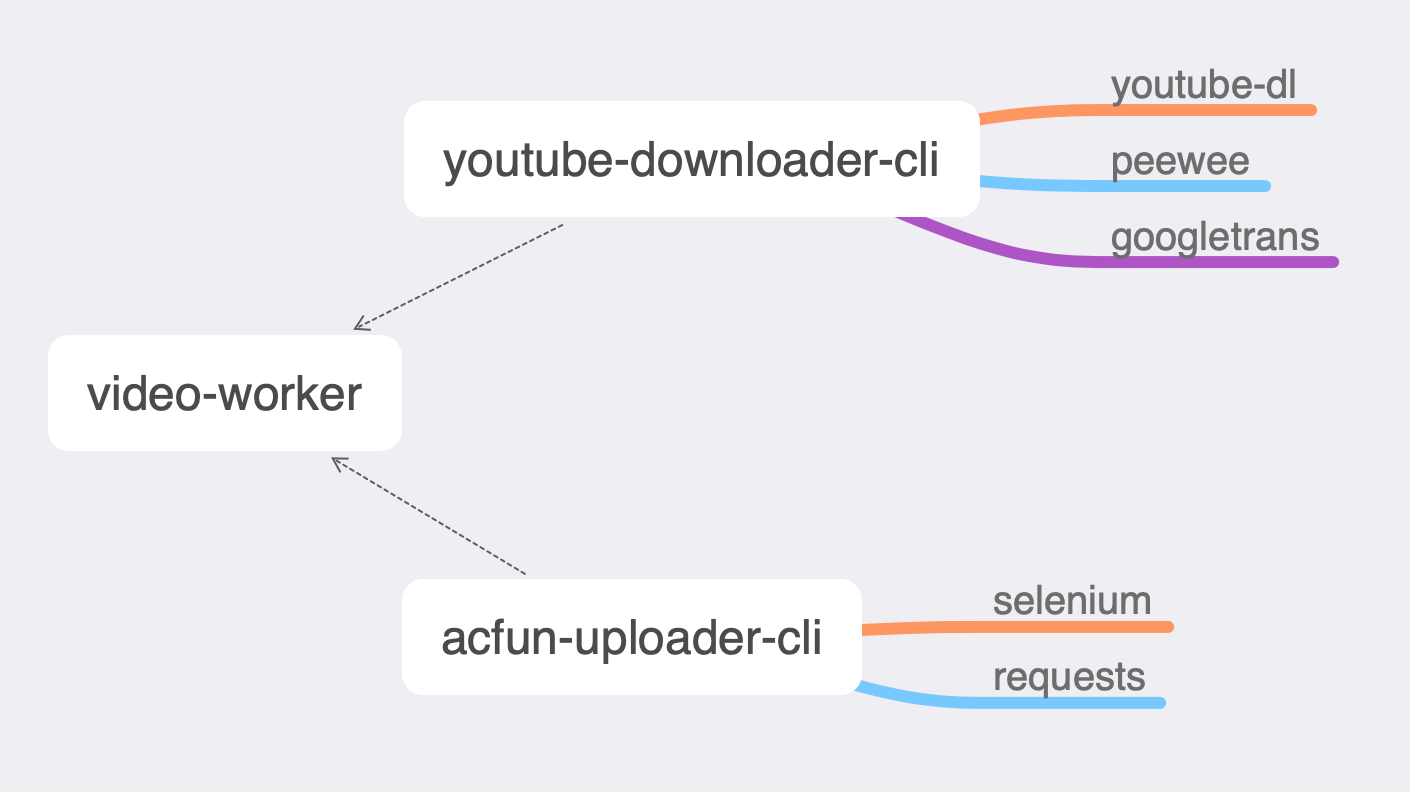
这个项目看起来只是在解决一个问题,但是其实是由三个小项目组成的,这一点倒是从头到尾都没变过,主要是为了逻辑的拓展,比如后期接入B站等上传的自动化逻辑。断断续续已经写了三个月多了,纯粹是为了自娱自乐。碰到了各种奇葩问题,也发现了一些有意思的东西。比如很多命令和参数设计完之后我自己都记不住,加入了justfile支持。
所有代码都托管在了Github,其中两个项目后来改成了Public,但是video-worker还是没有开源,还是因为那个原因。
- acfun-uploader-cli
- youtube-downloader-cli
- video-worker
➜ video-worker git:(master) ./main.py --help Usage: main.py [OPTIONS] COMMAND [ARGS]... Options: --help Show this message and exit. Commands: account Create and/or list accounts. add Parse and download the specified youtube videos. channel Load video platform channels. cleanup Clean up all the videos which has been uploaded to all the... configure Show the current configurations. platform List all the platforms' flags. remove Remove the specified type entities by id. run Start the downloader and uploader in alone threads. ➜ video-worker git:(master)
写这篇文章的过程中我有好几次想中断,不太想公布一些问题,毕竟涉及到crawler都会有些擦边球的意思,考虑到看到的人流量几乎可以忽略不计就还是发了吧。写出来的原本目的是这个项目写到现在这个时间节点上,我也需要捋一捋我自己的想法结构。